There's been an interesting discussion about Aggregates on the Italian DDD mailing lists. When things become complex, a simple example might just turn too simple. So I came up with this medium-sized one. Hope it won't be too long. Ok, so let's start from our first User Story
User Story #1: Placing an order
As a Customer
I Want to place an order
In order to purchase some goods
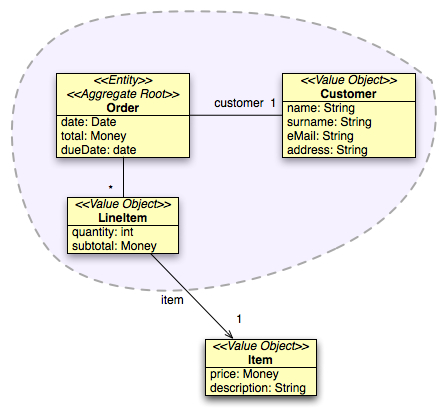
The simplest implementation of the story is essentially stateless: every time a customer wants to order something, needs to re-enter the data. In the DDD perspective, the resulting model is based on a single aggregate (we're deliberately ignoring the catalog for now) whose root is the Order class.
The stateless nature of the service makes it really easy to implement: a Customer is just a Value Object, created and eventually dropped at needs. Also we took some shortcut: we've chosen to implement Address as a String. Item is sort of natural value object, while LineItem is somewhat in the middle: we can change quantities, while the order is in open state, but we can implement this also using droppable Value Objects, easing the integrity burden for the aggregate root.
Some businesses (like buying train tickets) might just work like this, but our marketing is more inclined to manage customers in a more long-term way, so here are two more user stories.
User Story #2: Returning customer
As a Customer
I Want to retrieve my profile
In order to place more orders
Story #2 breaks our assumption about the aggregate boundaries. If we stick to the aggregate rule-of-thumb, if we want to delete an Order, we probably don't want to delete also the corresponding Customer. So we need a separate aggregate for that. What would happen if we decide to delete a Customer? Should we delete all orders? We don't have enough information to answer that, yet, we'll mark it as an outstanding question for our next meeting with the domain expert. Let's try the model with two aggregates and see how does it perform.
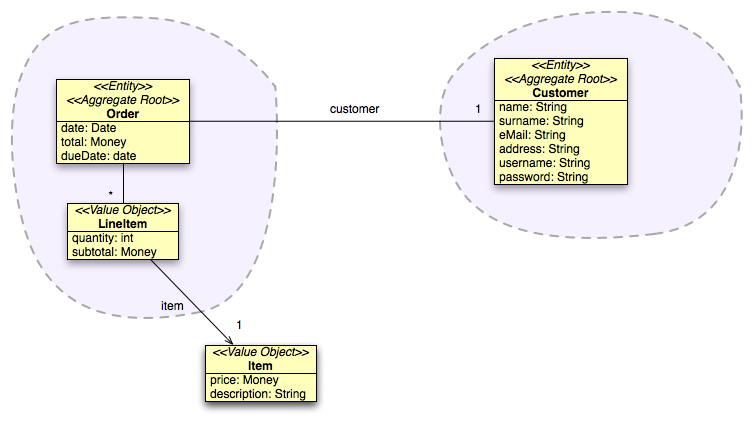
We now have a relationship crossing the aggregate boundary. We have promoted Customer to become the root of the newly created aggregate, so there is no potential integrity violation. Still we have to watch it closely, because this is where problems related to lazy/eager loading will arise. We also added username and password to Customer.
User Story #3: Different shipping address
As a Customer
I Want to specify a valid shipping address
In order to ship to a different destination
Multiple addresses are a call for a separate type to manage Address. We don't have so many responsibilities so far, for this class, except validation (which as Udi Dahan would say, doesn't necessarily belong to the domain layer) but the smell of duplication is probably enough to go for a separate class. We try to keep the model as simple as possible, so we treat Address like a value object.
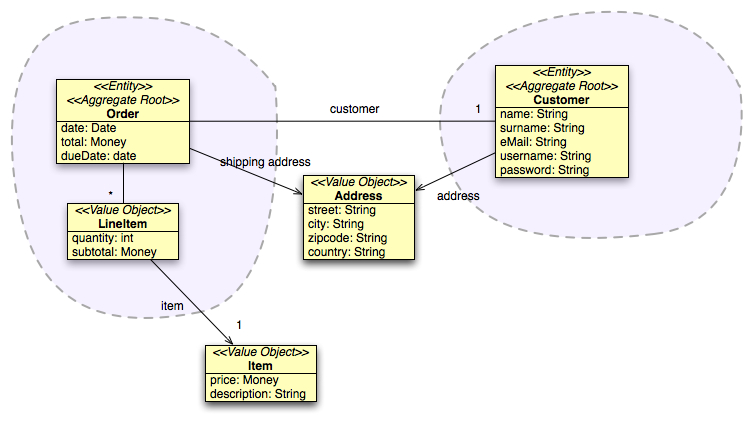
User Story #4: Editable customer profile
As a Customer
I Want to edit my profile
In order to update it if needed
Story #4 makes explicit what we've been suspecting: Customer needs to be an entity, because it has a nontrivial lifecycle. No revolutions at Domain Model level, but this triggers a question: "What happens if I have an outstanding order and the customer changes its data before the order is dispatched?" This is the type of questions you don't want to answer as software developer. So we walk up the stairs to have a talk with the Domain Expert. We come back with two fresh user stories:
User Story #5: Specify Billing and Shipping address
As a Customer
I Want to specify independent billing and shipping addresses
In order to deliver goods to different locations
This one is relatively easy: just reinforcing our design. We'll now have two references from Order to Address, which are managed by the Customer. We just store a default Address in the Customer aggregate (we could do better) but's ok for now.
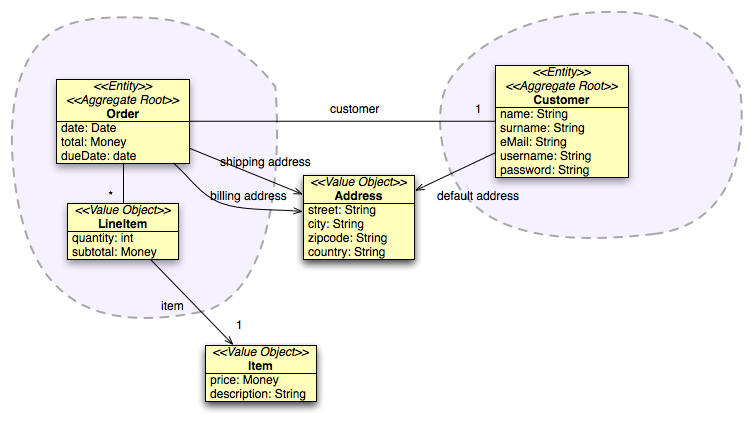
Story #6 is a little trickier, it comes from the legal department and tell us what we probably expected.
User Story #6: Track past orders
As a Legal Department
I Want to track orders
In order to in order to manage litigations
The domain expert state it clear: once an order is placed, it can't be changed in any of its parts, be it the content or the Customer. In case of litigation, it must behave exactly like printed paper. But Customer does not, its lifecycle is different from our needs, we'd need a separate class for that. We're lacking fantasy and call it CustomerData.
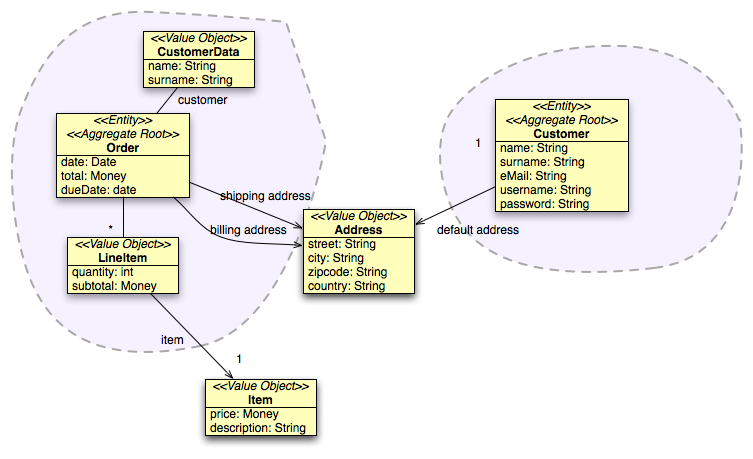
Everything is looking a lot different from the beginning. The two aggregates are now largely decoupled: we can change or delete an order without affecting the customer or deleting or unregistering a customer without losing tracks of its past orders. On the other hand we have explicit duplication here. Customer and CustomerData look so similar we're feeling guilty. Did we violate DRY principle? At first look the data is the same, but if we think about behavior, or class lifecycle, Customer and CustomerData are clearly two different beasts. But more often than not, when the starting point is the data model, instead of the domain model we end up thinking that's the same data, hence the same class. I bet experienced data modelers do not fall into these pitfalls as well, but I've seen these problems recurring quite often.
Once we accept that little bit of data duplication we have a system which is a lot easier to evolve and maintain, with aggregate roots as integrity enforcers within their boundaries, and agnostic about the rest.
To add some salt, don't forget aggregates are also building blocks of distributed systems: suppose we'll need to send orders to a remote system. Sending just the single aggregate and the referenced value objects is probably the cleanest way.